Spark搭建
JAVA安装与环境搭建
ssh安装与测试
单机Spark可略过
略
hadoop安装与配置(可跳过)
- Apache Hadoop下载(binary文件)
- 解压放到/home/zydar/software下(不建议放在/usr下)
配置JAVA_HOME
#export JAVA_HOME=${JAVA_HOME} export JAVA_HOME=/usr/lib/java/jdk1.8.0_101配置/etc/profile:export HADOOP_HOME,PATH追加:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
JAVA_HOME=/usr/lib/java/jdk1.8.0_101 JRE_HOME=$JAVA_HOME/jre HADOOP_HOME=/usr/local/bin/hadoop-2.7.3 PATH=$PATH:$JAVA_HOME/bin:$JRE_HOME/bin:$HADOOP_HOME/bin export JAVA_HOME export JRE_HOME export HADOOP_HOME export PATH验证
hadoop versionwordcount测试
cd $HADOOP_HOME sudo mkdir input cp etc/hadoop/* input hadoop jar ./share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.3.jar wordcount input /home/zydar/output cat /home/zydar/output/* rm -r /home/zydar/output rm -r input伪分布Hadoop配置
配置core-site.xml,hdfs-site.xml,yarn-site.xml,mapred-site.xml
【core-site.xml】 <configuration> <property> <name>fs.default.name</name> <value>hdfs://localhost:8082</value> </property> </configuration> 【hdfs-site.xml】 <configuration> <property> <name>dfs.replication</name> <value>1</value> </property> <property> <name>dfs.namenode.name.dir</name> <value>/usr/local/hadoop/hadoop-2.6.4/dfs/name</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>/usr/local/hadoop/hadoop-2.6.4/dfs/data</value> </property> </configuration> 【yarn-site.xml】 <configuration> <property> <name>yarn.nodemanager.aux.services</name> <value>mapreduce_shuffle</value> </property> </configuration> 【mapred-site.xml】(cp mapred-site.xml.template mapred-site.xml) <configuration> <property> <name>mapreduce.framwork.name</name> <value>yarn</value> </property> </configuration>格式化
bin/hadoop namenode -format启动/关闭hadoop
start-all.sh/stop-all.shjps查看JAVA进程
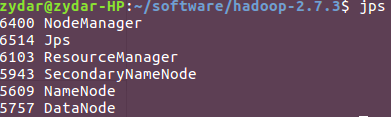
查看hadoop
localhost:50070
localhost:8088/cluster
hdfs dfsadmin -report
伪分布wordcount测试
hdfs dfs -mkdir -p input hdfs dfs -put etc/hadoop input hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.6.4.jar wordcount input/hadoop output hdfs dfs -cat output/* hdfs dfs -rm -r input hdfs dfs -rm -r output
Spark安装与配置
- Spark下载
- 解压放到/home/zydar/software下(不建议放在/usr下)
- 配置/etc/profile:export SPARK_HOME,PATH追加:$SPARK_HOME/bin
配置环境
cp ./conf/spark-env.sh.template ./conf/spark-env.sh vim ./conf/spark-env.shexport JAVA_HOME=/usr/lib/java/jdk1.8.0_101
export SPARK_MASTER_IP=125.216.238.149
export SPARK_WORKER_MEMORY=2g
export HADOOP_CONF_DIR=/home/zydar/software/hadoop-2.7.3/etc/hadoop
启动Spark
./sbin/start-all.shlocalhost:8080查看Spark集群
- 新建job(localhost:4040)
pyspark --master spark://zydar-HP:7077 --name czh --executor-memory 1G --total-executor-cores 2 >>> textFile = sc.textFile("file:///home/zydar/software/spark-2.0.0/README.md") >>> textFile.count() >>> textFile.filter(lambda line: line.split(' ')).map(lambda word: (word,1)).reduceByKey(lambda a,b: a+b).map(lambda (a,b): (b,a)).sortByKey(False).map(lambda (a,b): (b,a)).collect()
Spark IDE开发环境
- 配置/etc/profile:export PYTHONPATH
PYTHONPATH=$PYTHONPATH:$SPARK_HOME/python:$SPARK_HOME/python/lib/py4j-0.10.1-src.zip
Spark on Pycharm
- 下载Python(推荐.edu账号注册免费使用Professional版)
- 解压放到/home/zydar/software下(不建议放在/usr下)
运行
./bin/pycharm.sh测试代码
from pyspark import SparkContext,SparkConf #conf = SparkConf().setAppName("YOURNAME").setMaster("local[*]") conf = SparkConf().setAppName("YOURNAME").setMaster("spark://zydar-HP:7077").set("spark.executor.memory", "1g").set("spark.cores.max", "2") sc = SparkContext(conf=conf) localFile = "file:///home/zydar/software/spark-2.0.0/README.md" hdfsFile = "README.md" hdfsFile1 = "/user/zydar/README.md" textFile = sc.textFile(localFile) print textFile.count()
Spark on Ipython Notebook
Ipython Notebook安装与配置
apt-get install ipython#安装ipython apt-get install ipython-notebook#安装ipython notebook ipython profile create spark#创建spark的config记下生成的路径
/home/zydar/.ipython/profile_spark/ipython_notebook_config.py进入ipython设置密码
ipython In [1]:from IPython.lib import passwd In [2]:passwd()记下返回的sha1
进入ipython_notebook_config.py文件
c.NotebookApp.password = u'sha1:67c34dbbc0f8:a96f9c64adbf4c58f2e71026a4bffb747d777c5a' c.FileNotebookManager.notebook_dir = u'/home/zydar/software/data/ipythonNotebook' # c.NotebookApp.open_browser = False打开Ipython Notebook
ipython notebook --profile=spark测试代码(同Pycharm)